At Cloud Sultans, our mission is to help small and large businesses to better collaborate and achieve high productivity with their teams by maximizing the power of Google Workspace (formerly GSuite). Today, we’re diving into one of the most exciting frontiers in technology: how Large Language Models (LLMs) and AI agents are transforming unstructured data into smart, structured insights.
Why Unstructured Data Is a Challenge
In our data-driven world, businesses are drowning in documents—emails, PDFs, contracts, reports, and spreadsheets. While this information is critical for operations and decision-making, most of it exists in unstructured formats. That means it’s not neatly organized into tables or databases, making it hard for traditional software to process or extract value from. These documents can contain everything from simple text to complex tables spanning multiple pages.
To unlock this data, businesses have historically relied on tools like Optical Character Recognition (OCR), which convert images of text into actual text. However, OCR doesn’t provide semantic understanding. It simply translates pixels to words without recognizing relationships, meanings, or context. That’s where LLMs and AI agents come in.
Document Complexity: More Than Meets the Eye
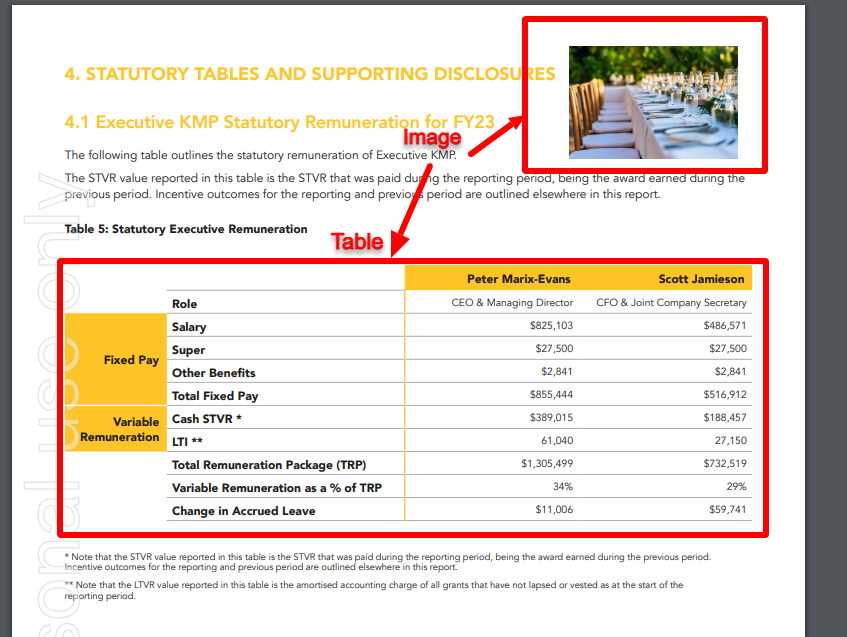
It’s tempting to think of documents as basic text files, but business documents often contain complex structures—multi-page tables, images, embedded metadata, and hierarchical relationships with other documents. For instance, a contract might reference multiple amendments, invoices, and purchase orders, all of which relate to each other. A simple text extraction is not enough—you need a system that understands how everything connects.
Some documents can be 600 pages long, containing tens of thousands of words and intricate relationships between tables and paragraphs. Without intelligent processing, valuable insights remain buried in these dense documents. Traditional data pipelines are simply not built for this level of complexity.
Document Hierarchies: Vertical and Horizontal Relationships
One of the most fascinating aspects of document management is understanding how documents relate to each other. These relationships fall into two categories:
- Vertical Hierarchies: A master agreement leading to statements of work, amendments, and related invoices. Understanding these connections is key to grasping the full picture of a transaction or legal engagement.
- Horizontal Hierarchies: Think of research papers that cite previous works and lead to patents or product documentation. Or supply chain documents like bills of lading, certificates of insurance, and shipping receipts—all tied to the same shipment but documented separately.
An intelligent system needs to not just read each document, but interpret the relationships between them, often across departments and data sources.
The Breakthrough: Large Language Models
Enter Generative Pre-trained Transformers (GPTs)—the foundation of today’s LLMs. These models are trained on vast amounts of data and built to understand human language at a deep level. They work by converting language into mathematical representations (tokens) that can be analyzed in multi-dimensional space.
With over 600 billion parameters, these models can detect patterns, understand nuances, and generate human-like responses. More importantly, they allow us to embed, vectorize, and analyze documents in a way that mimics human reading—but at machine speed and scale.
Turning Text into Data: The Expansion-Contraction Model
Transforming a document into structured data is not a simple compression task. In fact, it begins with expansion. When OCR and NLP tools process a document, they increase the amount of data exponentially—turning a 1,000-word PDF into potentially millions of tokens.
Only after this expansion do LLMs begin to identify what’s important. They distill the chaos into a manageable and relevant data model, identifying key data points—like names, dates, numbers, or relationships—that actually matter for business decisions. The goal isn’t to summarize, but to extract structured meaning from noisy data.
AI Agents: Modular Intelligence at Work
To handle such complexity, we don’t rely on a single monolithic AI—we use modular AI agents, each specialized in a specific task. Here’s how they work:
1. The Inspection Agent
This agent takes a first pass at the document, analyzing metadata, file size, structure, and embedded elements. It prepares the groundwork for deeper analysis by other agents.
2. The OCR Agent
Next, this agent converts visual elements into machine-readable text. Modern OCRs are extremely accurate and can handle complex formats like scanned tables or handwritten notes.
3. The Vectorization Agent
Once text is extracted, the vectorization agent uses an LLM to tokenize and embed the data in vector space. This step is crucial for enabling semantic understanding and later querying.
4. The Splitter Agent
Often, businesses store multiple documents in a single file. The splitter agent identifies logical document breaks and separates them for cleaner analysis.
5. The Extract Agent
This is the brain of the system. It uses LLM prompts to identify key data points based on your business needs—pulling out the client name, contract amount, delivery date, or any other relevant element.
6. The Matching Agent
Finally, the matching agent links documents together—establishing the vertical and horizontal hierarchies we mentioned earlier. It uses metadata, content analysis, and contextual clues to associate related files.
From Traditional to Agentic Workflows
In the past, data pipelines were deterministic: data flowed in one direction through a series of hard-coded steps. But AI agents introduce agentic workflows—autonomous, event-driven systems that respond to real-time data and collaborate with each other.
In these modern systems, agents are loosely coupled. One agent’s output might trigger another’s action. This approach offers several advantages:
- Scalability: Agents can work in parallel, speeding up processing.
- Autonomy: Systems can operate without human supervision.
- Flexibility: You can swap or upgrade agents as technologies evolve.
- Non-determinism: Agents can explore multiple possibilities before deciding on the most likely or relevant output.
A New Era for Document Intelligence
By combining LLMs and AI agents, we’re entering a new era of document intelligence—where unstructured data is no longer a roadblock but a resource. Imagine being able to query thousands of documents as easily as you ask a chatbot. Or automatically linking all documents related to a client, contract, or transaction with zero manual effort.
For Google Workspace users, this means you can supercharge your Drive, Gmail, and Docs with intelligent layers of automation and AI—making your daily operations smoother, smarter, and more responsive.
Any questions, comments, or reactions about our article, we’re happy to hear that in the comment section below.
We always love diving into healthy discussions. If you also feel that you haven’t been using Google Workspace at its best, reach us at (Cloud Sultans : contact@cloudsultans.com).
We offer free consultation or system audit to find you the best possible solution.



